YourTTS - Swiss knife for Text-to-Speech
YourTTS #
The recent surge of new end-to-end deep learning models has enabled new and exciting Text-to-Speech (TTS) use-cases with impressive natural-sounding results. However, most of these models are trained on massive datasets (20-40 hours) recorded with a single speaker in a professional environment. In this setting, expanding your solution to multiple languages and speakers is not feasible for everyone. Moreover, it is particularly tough for low-resource languages not commonly targeted by mainstream research. To get rid of these limitations and bring zero-shot TTS to low resource languages, we built YourTTS, which can synthesize voices in multiple languages and reduce data requirements significantly by transferring knowledge among languages in the training set. For instance, we can easily introduce Brazilian Portuguese to the model with a single speaker dataset by co-training with a larger English dataset. It makes the model speak Brazilian Portuguese with voices from the English dataset, or we can even introduce new speakers by zero-shot learning on the fly.
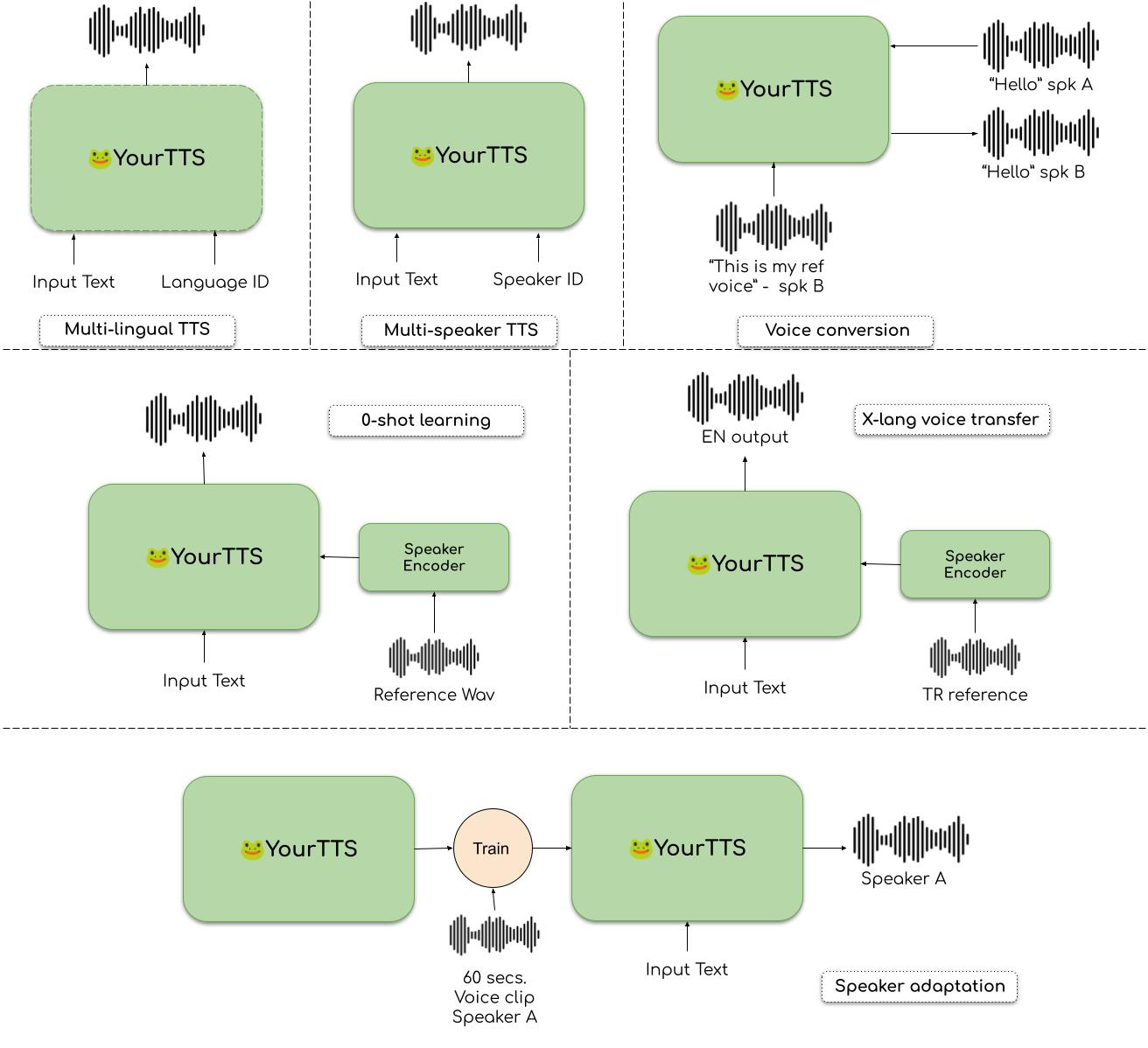
In “YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone” we introduce the YourTTS that targets,
- Multi-Lingual TTS. Synthesizing speech in multiple languages with a single model.
- Multi-Speaker TTS. Synthesizing speech with different voices with a single model.
- Zero-Shot learning. Adapting the model to synthesize the speech of a novel speaker without re-training the model.
- Speaker/language adaptation. Fine-tuning a pre-trained model to learn a new speaker or language. (Learn Turkish from a relatively smaller dataset by transferring knowledge from learned languages)
- Cross-language voice transfer. Transferring a voice from its original language to a different language. (Using the voice of an English speaker in French)
- Zero-shot voice conversion. Changing the voice of a given speech clip.
Model Architecture #
YourTTS is an extension of our previous work SC-GlowTTS. It uses the VITS (Variational Inference with adversarial learning for end-to-end Text-to-Speech) model as the backbone architecture and builds on top of it. We use a larger text encoder than the original model. Also, YourTTS employs a separately trained speaker encoder model to compute the speaker embedding vectors (d-vectors) to pass speaker information to the rest of the model. We use the H/ASP model as the speaker encoder architecture. See the figure below for the overall model architecture in training (right) and inference (left).
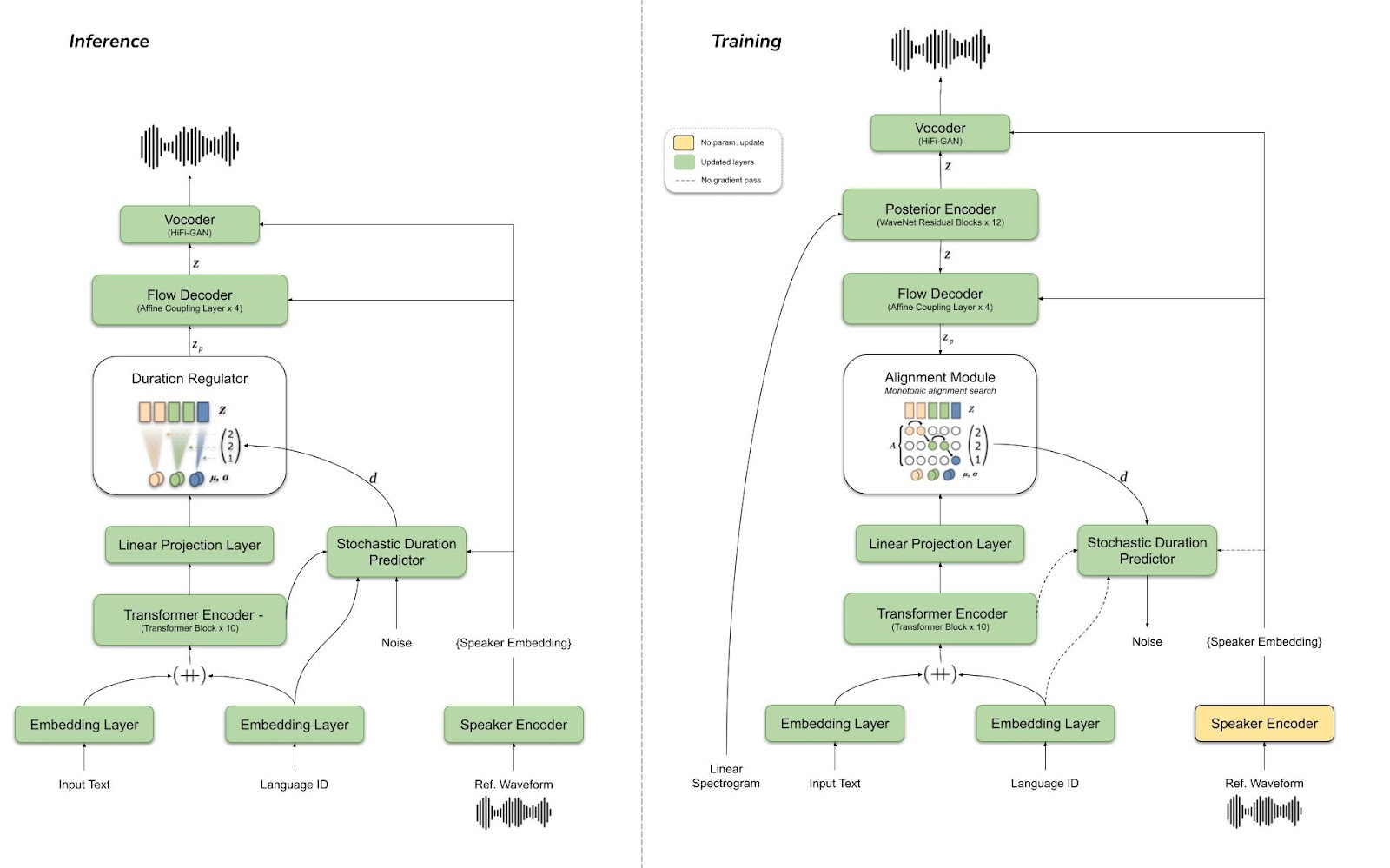
VITS is a peculiar TTS model as it employs different deep-learning techniques together (adversarial learning, normalizing flows, variational auto-encoders, transformers) to achieve high-quality natural-sounding output. It is mainly built on the GlowTTS model. The GlowTTS is light, robust to long sentences, converges rapidly, and is backed up by theory since it directly maximizes the log-likelihood of speech with the alignment. However, its biggest weakness is the lack of naturalness and expressivity of the output.
VITS improves on it by introducing specific updates. First, it replaces the duration predictor with a stochastic duration predictor that better models the variability in speech. Then, it connects a HifiGAN vocoder to the decoder’s output and joins the two with a variational autoencoder (VAE). That allows the model to train in an end2end fashion and find a better intermediate representation than traditionally used mel-spectrograms. This results in high fidelity and more precise prosody, achieving better MOS values reported in the paper.
Note that both GlowTTS and VITS implementations are available on 🐸TTS.
Dataset #
We combined multiple datasets for different languages. We used VCTK and LibriTTS for English (multispeaker datasets), TTS-Portuguese Corpus (TPC) for Brazilian Portuguese, and the French subset of the M-AILABS dataset (FMAI).
We resample the audio clips to 16 kHz, apply voice activity detection to remove silences, and apply RMS volume normalization before passing them to the speaker encoder.
Training #
We train YourTTS incrementally, starting from a single speaker English dataset and adding more speakers and languages along the way. We start from a pre-trained model on the LJSpeech dataset for 1M steps and continue with the VCTK dataset for 200K steps. Next, we randomly initialize the new layers introduced by the YourTTS model on the VITS model. Then we add the other datasets one by one and train for ~120K steps with each new dataset.
Before we report results on each dataset, we also fine-tune the final model with speaker encoder loss (SCL) on that particular dataset. SCL compares output speech embeddings with the ground truth embeddings computed by the speaker encoder with cosine similarity loss.
We used a single V100 GPU and used a batch size of 64. We used the AdamW optimizer with beta values 0.8 and 0.99 and a learning rate of 0.0002 decaying exponentially with gamma 0.999875 per iteration. We also employed a weight decay of 0.01.
Results #
We run “mean opinion score” (MOS) and similarity MOS tests to evaluate the model performance. Also, we use the speaker encoder cosine similarity (SECS) to measure the similarity between the predicted outputs and the actual audio clips of a target speaker. We used a 3rd party library for SECS to be compatible with the previous work. We avoid details of our experiments for the sake of brevity. Please refer to the paper to see the details.
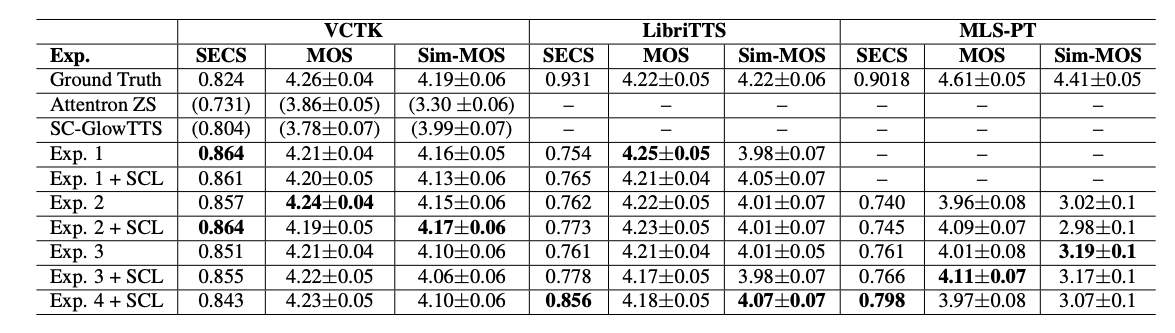
Table (1) above shows our results on different datasets. Exp1 is trained with only the VCTK. Exp2. is with the VCTK and TPC. Then, we add the FMAI, LibriTTS for Exp3. and Exp4, respectively. The ground truth row reports the values for the real speaker clips in respective datasets. Finally, we compare our results with AttentronZS and SC-GlowTTS. Note that SC-GlowTTS is our previous work that leads our way to the YourTTS (You can find its implementation under 🐸TTS). We achieve significantly better results than the comparing work in our experiments. MOS values are on-par or even better than the ground truth in some cases, which is even surprising for us to see.
Table (2) depicts the zero-shot voice conversion (ZSVC) results between languages and genders by the speaker embeddings. For ZSVC, we pass the given speech clip from the posterior encoder to compute the hidden representation and re-run the model in the inference mode again conditioned on the target speaker’s embedding. You see in the table the model’s performance between languages and genders. For instance, “ en-pt” shows the results for converting the voice of a Portuguese speaker by conditioning on an English speaker. And “M-F” offers the conversion of a Male speaker to a Female speaker.

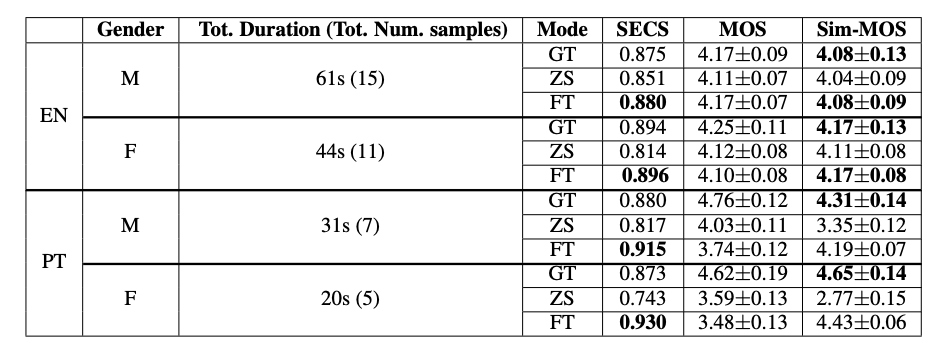
Table (3) yields the results for the speaker adaptation experiments where we fine-tune the final YourTTS model by SCL on different length clips of a particular novel speaker. For instance, the top row shows the results for a model trained on a male English speaker with 61 seconds of an audio clip. GT is the ground truth, ZS is zero-shot with only the speaker embeddings, and FT is fine-tuning. These results show that our model can achieve high similarity when fine-tuned with only 20 seconds of audio sample from a speaker in case mere use of speaker embeddings is not enough to produce high-quality results.
Due to the time and space constraints in the paper, we could not expand the experiments to all the possible use-cases of YourTTS. We plan to include those in our future study and add new capabilities to YourTTS that would give more control over the model.
Try out YourTTS #
YourTTS is open-source and available in 🐸TTS with a training recipe and a pre-trained model. You can train your own model, synthesize voice with the pre-trained model or finetune it with your dataset.
Visit our demo page accompanying this blog post give YourTTS a try right on your browser.
You can also sign up coqui.ai and start using the updated high-quality version of YourTTS.
Ethical Concerns #
We are well aware that the expansion of the TTS technology enables various kinds of malign uses of the technology. Therefore, we also actively study different approaches to prevent or at the very least put more fences along the way of the misuse of the TTS technology.
To exemplify this, on our demo page, we add background music to avert the unintended use of the voice clips on different platforms.
If you also want to contribute to our research & discussion in this field, join us here.
Conclusion #
YourTTS can achieve competitive results on multi-lingual, multi-speaker TTS, and zero-shot learning. It also allows cross-language voice transfer, learning new speakers and languages from relatively more minor datasets than the traditional TTS models.
We are excited to present YourTTS and see all the different use-cases that 🐸 Community will apply. As always, feel free to reach out for any feedback.
👉 Try out YourTTS on Coqui.ai
👉 Visit YourTTS project page
👉 Try YourTTS on Colab
👉 Try voice conversion with YourTTS on Colab